We will see you here at Polytechnique Montréal!
Please read the access guide for how to visit by car or public transportation.
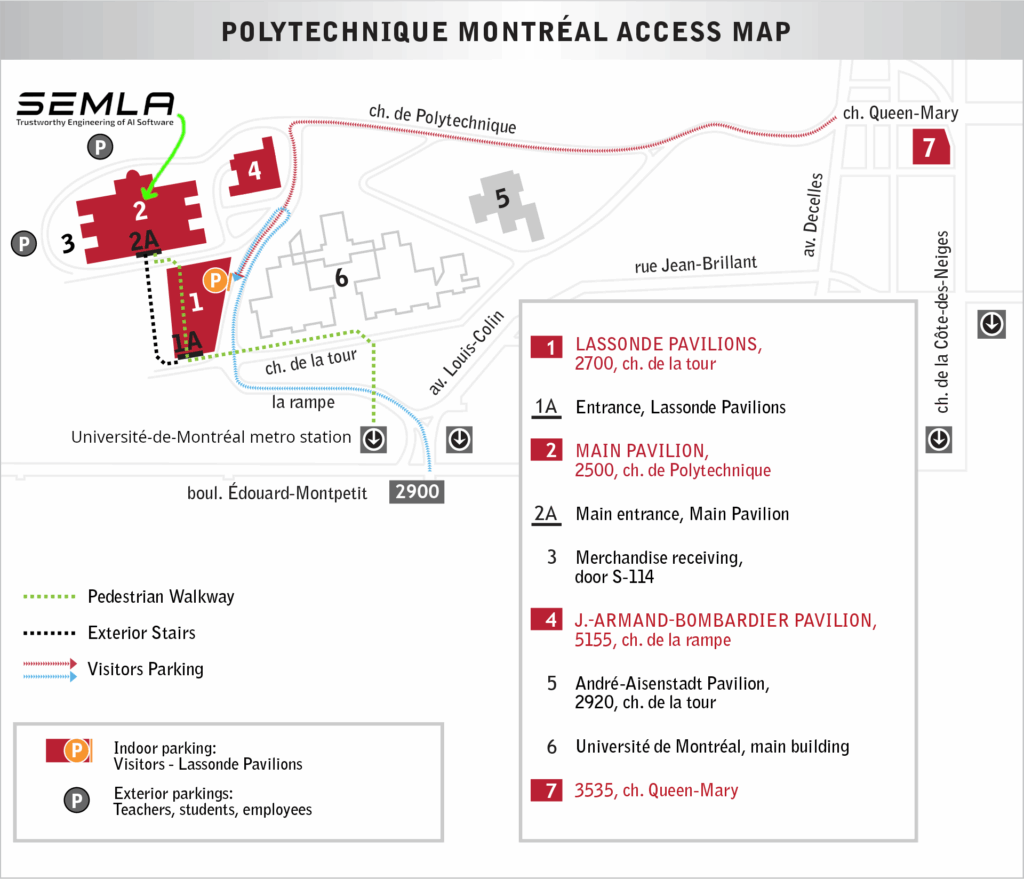
The event will be in the Pavilion Principal (the main building). It is marked with a ‘2’ on the image below.
Please read the access guide for how to visit by car or public transportation.
The event will be in the Pavilion Principal (the main building). It is marked with a ‘2’ on the image below.